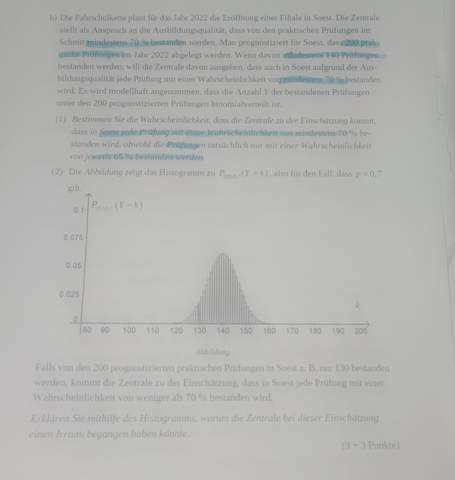
Die gegebene Aufgabe ist: Eine Urne ist mit q schwarzen und r roten Kugeln befüllt. Es wird mit Zurücklegen und ohne Berücksichtigung der Reihenfolge gezogen.
Wie hoch ist die Wahrscheinlichkeit, beim Ziehen von l+m Kugeln genau l schwarze und m rote Kugeln zu ziehen?
Mein 1. Ansatz:
Einführen einer Zufallsgröße X, die die schwarzen gezogenen Kugeln zählt und binomialverteilt ist mit n = q+r und p = l/(q+r). Die gesuchte Wahrscheinlichkeit ist nun P(X=l). Ist dieser Ansatz so korrekt?
Mein 2. Ansatz:
Prinzipiell kann man ja auch damit arbeiten, dass bei Laplace Experimenten die Wahrscheinlichkeit berechnet werden kann, indem man die Anzahl an günstigen Ergebnissen durch die Anzahl an insgesamt möglichen Ergebnissen teilt.
Es gibt insgesamt (q+r)^(l+m) / (l+m)! Möglichkeiten, aus q+r Kugeln genau l+m Kugeln auszuwählen (mit Zurücklegen und ohne Berücksichtigung der Reihenfolge).
Es gibt (q)^(l) / l! Möglichkeiten, aus q Kugeln genau l Kugeln auszuwählen. Und es gibt (r)^(m) / m! Möglichkeiten, aus r Kugeln genau m Kugeln auszuwählen. Folglich gibt es ((q)^(l) / l!) * ((r)^(m) / m!) Möglichkeiten, aus q schwarzen Kugeln genau l schwarze Kugeln und gleichzeitig aus r roten Kugeln genau m rote Kugeln auszuwählen (mit Zurücklegen und ohne Berücksichtigung der Reihenfolge. Die Terme sind analog zum Fall ohne Zurücklegen und ohne Berücksichtigung der Reihenfolge aufgestellt).
D.h. die gesuchte Wahrscheinlichkeit lässt sich auch als
(Möglichkeiten, aus q+r Kugeln genau l+m Kugeln auszuwählen)/(Möglichkeiten, aus q schwarzen Kugeln genau l schwarze Kugeln und gleichzeitig aus r roten Kugeln genau m rote Kugeln auszuwählen)
= ( (q+r)^(l+m) / (l+m)!) /
((q)^(l) / l!) * ((r)^(m) / m!) ) ausdrücken, oder?
Ist das so korrekt, oder sind mir irgendwo Fehler unterlaufen? Sind beide Ansätze zulässig?