Moin,
ich habe für meine Bachelorarbeit eine Onlineumfrage in meinem Unternehmen durchgeführt. Hierbei habe ich speziell den Teilzeitkräften im Unternehmen einige Fragen gestellt. Mittlerweile habe ich die Umfrageergebnisse erhalten und die Auswertung lief bisher auch reibungslos.
Nur bei einer Fragengruppe stehe ich etwas auf dem Schlauch und komme in diesem Zusammenhang auch nicht weiter.
Die Fragengruppe bezog sich auf die Gründe, warum Teilzeitkräfte in Teilzeit arbeiten. Hierbei habe ich in Form von Matrixfragen gefragt, ob bestimmte Gründe für die Wahl einer Teilzeitbeschäftigung von großer, kleiner oder keiner Bedeutung waren. Dieser Fragebogen wurde von meinen Dozenten und der Personalentwicklungsabteilung abgesegnet und als gut befunden.
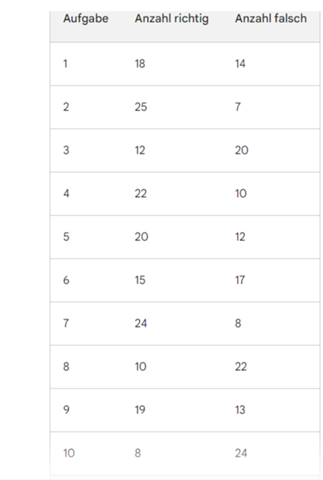
Bei der Auswertung fällt mir jetzt aber immer mehr auf, dass ich als Antwortmöglichkeit lieber eine numerische Skalenbewertung von 1 - "keine Bedeutung" bis 6 "große Bedeutung" hätte wählen sollen. Bei der Auswertung habe ich nun zwischen den Auswahlmöglichkeiten "große Bedeutung" und "kleine Bedeutung" differenziert und für die jeweiligen demografischen Gruppen im Unternehmen zum einen Statistiken gebildet, die nur den prozentualen Anteil der Angabe "Große Bedeutung" aller Antworten bei jedem Grund aufzeigen und zum anderen Statistiken erstellt, die nur die prozentualen Angaben mit der Bewertung "kleine Bedeutung" von allen Antworten aufzeigen. Die Antwortmöglichkeiten und die Auswertung als solche erscheint mir zum jetzigen irgendwie als unwissenschafltich und bei der Auswertung auch als ziemlich umständlich und unübersichtlich.
Die wichtigste Frage, die bei mir nun besteht ist die Frage, wie ich im methodischen Teil wissenschaftlich erklären kann, warum ich ich bei dieser Fragekategorie die Auswahlmöglichkeiten so genommen habe, wie ich Sie genommen haben. Je weiter ich mich mit dem Thema befasse, desto unsicherer werde ich nämlich bei dieser Frage. Leider kann ich die Befragung auch nicht rückgängig machen und ich muss jetzt mit den Daten so arbeiten, wie ich Sie jetzt haben.
Abgesehen davon Frage ich mich, in wieweit meine Auswertung nun valide ist. Gibt es eventuell andere bzw. wissenschaftlicherer und übersichtlichere Möglichkeiten, die Antworten auszuwerten oder habe ich bisher die beste Möglichkeit schon angewendet, indem ich zwischen den Antwortmöglichkeiten differenziert haben?
Leider hat sich herausgestellt, dass mein Dozent im Bereich Statistik keine wesentlichen Kenntnisse hat. Dementsprechend kann er mir bei diesem Problem nicht helfen. Vielleicht findet sich ja hier jemand, der mehr Ahnung hat und mit weiterhelfen kann.
Ich bedanke mich im Voraus für die Antwort!
Viele Grüße