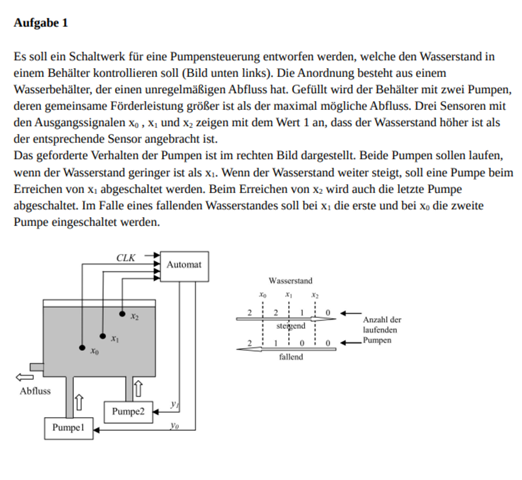
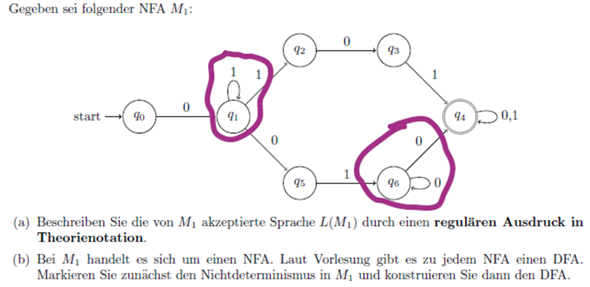
Also für alle, die nicht wissen, was es ist, es ist eines der Millenium Probleme, welches noch nicht gelöst wurde.
Kurze Zusammenfassung der Frage des P-NP Problems:
Bedeutet die Fähigkeit, korrekte Antworten schnell zu erkennen (NP) auch, dass es eine schnelle Möglichkeit gibt, diese Antworten zu finden (P)?
Beispiel:
Man hate einen Zauberwürfel mit auf jeder Seite hunderten Feldern, sobald er "gelöst" wird, kann man schnell erkennen, ob er richtig oder falsch gelöst wurde, allerdings würde man (nach dem heutigen Wissensstand) nahezu ewig brauchen, um ihn überhaupt lösen zu können, die Frage ist da halt: gibt es eine Möglichkeit, ihn schnell lösen zu können, da man ja auch schnell sehen kann, ob er richtig oder falsch gelöst ist.
Meine "Lösung" (als Gedankenexperiment; noch nicht rechnerisch nachgewiesen):
Man will ein Passwort hacken, weshalb man einen Algorithmus schreibt, welcher die Passwörter einzeln durchgeht (Problem in NP). Da wird ja schnell erkannt, ob ein Passwort richtig oder falsch ist (dadurch, dass man dann eingeloggt ist oder eben nicht), allerdings gibt es keine Möglichkeit, es anders herauszufinden, da es eben einfach keinen anderen Lösungsweg gibt. Also gibt es auch keinen schnelleren Lösungsweg, weshalb nur an diesem Beispiel theoretisch nachgewiesen wäre, dass P≠NP ist oder?
Ich würde mich über sachliche Antworten sehr freuen, mir ist bewusst, dass meine Antwort vermutlich viel zu einfach ist, damit sie als Lösung gesehen werden könnte und das andere Leute diese Idee vermutlich auch schon hatten. Mich würden nur eure Gedanken dazu interessieren!