Eigentlich könnte man ja meinen, dass dieses Problem recht leicht zu lösen sein müsste.
Aber aus irgendwelchen Gründen ist es das nicht, da " irgendwie für alles einen Sonderstatus hat.
Also was ich gerne wissen würde:
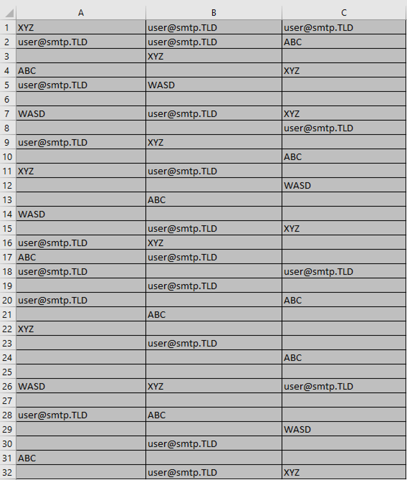
Wie bzw. mit welchem regulären Ausdruck kann man (z.b mit einem Grepbefehl?) alle Zeilen suchen, die mit einem " anfangen ohne, dass dies zu unerwarteten Verhalten führt und z.b der Pfad nicht mehr gefunden wird bzw. keine Ausgabedatei erzeugt wird?
Ich hab es jetzt bereits mit dutzenden verschiedensten Varianten versucht: grep '^"' grep '^\"' grep -E '^\"' grep '^\".*'
und noch X weiteren Variationen, aber entweder werden einfach nur alle Zeilen ausgegeben, die irgendwo im Text ein " enthalten oder es gibt Probleme mit der Erzeugung der Ausgabedatei.
Wichtig wäre in diesem Fall jedoch, dass nur der Anfang (erste Charakter) einer Zeile überprüft bzw. gematched werden soll. Scheinbar soll dies bei Grep ja mit ^ möglich sein und ein Escapen der " mit \. Funktioniert aber alles nicht!
GPT hab ich auch schon gefragt, aber der Bot ist mit der Frage komplett überfordert und gibt nur hanebüchenen Mist aus, der entweder nicht funktioniert oder sehr langsam ist (z.b Ansätze mit Powershell)
Also bevor ich jetzt noch meinen kompletten PC / CPU zu Schrott fahre: Gibt es eine effektive und schnelle Möglichkeit wie man diese Operation aus einer Textdatei alle Zeilen ohne " am Anfang = delete (möglichst mit verfügbaren Onboardmitteln) ausführen kann und falls ja wie?
Im Idealfall sollten die Zeilen, die nicht gematched werden auch einfach direkt aus der Datei herausgelöscht werden können, anstatt jedesmal den kompletten Inhalt zu kopieren.
Irgendein Tipp?