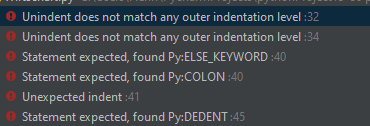
Hallo, ich programmiere gerade für mich eine art strasen rennen mit einem neuronalen netzt. das soll aber wirklich ein zeitaufwendiges projekt werden. aber jetzt brauch ich hilfe bei der strase. Ich will einen strasen kurs programmieren der schon bisschen lang ist, damit die autos auch fahren könne. kann mir villeicht jemand helfen weil sonst schaff ich das nicht. ich brauch sonst ewig dafür. also lasst euch von den roten linien nicht verwirren, aber es wäre perfekt wenn ihr einen strasen weg programmieren könntet mir kurven und allem drum und dran so wie zum teil schon in meinem code. Ausenrum um die strase soll eine blaue linie führen. Ein dickes dickes DANKE wenn das jemand schaffen würde, weil ich schaffs nicht. Da bin ich noch zu unerfahren. Deshalb wird das neuronales netzt unendlich dauern. Hier mein code :
import tkinter as tk
import math
class Ball:
def __init__(self, canvas, color, size, x, y):
self.canvas = canvas
self.color = color
self.size = size
self.x = x
self.y = y
self.id = canvas.create_oval(x, y, x+size, y+size, fill=color)
self.lines = [self.canvas.create_line(x, y, x, y, fill='red') for _ in range(5)]
self.text = self.canvas.create_text(x, y, text="", fill="black")
def update_lines(self):
angles = [random.uniform(math.radians(-80), math.radians(80)) for _ in range(5)]
distances = []
for i, (line, angle) in enumerate(zip(self.lines, angles)):
end_x = self.x + self.size/2 + 1000*math.cos(angle)
end_y = self.y + self.size/2 - 1000*math.sin(angle)
if end_y < road_top:
end_y = road_top
elif end_y > road_bottom:
end_y = road_bottom
self.canvas.coords(line, self.x + self.size/2, self.y + self.size/2, end_x, end_y)
distances.append(min(abs(self.y + self.size/2 - road_top), abs(self.y + self.size/2 - road_bottom)))
min_distance = min(distances)
self.canvas.itemconfig(self.text, text=str(min_distance), state='normal')
def hide_text(self):
self.canvas.itemconfig(self.text, state='hidden')
def create_ball(canvas, size, y):
x = 0
return Ball(canvas, 'green', size, x, y)
root = tk.Tk()
canvas_width = 400
canvas_height = 300
ball_size = 10
road_top = canvas_height/2 - 50
road_bottom = canvas_height/2 + 50
canvas = tk.Canvas(root, width=canvas_width, height=canvas_height)
canvas.pack()
# Draw the road
canvas.create_rectangle(0, road_top, canvas_width, road_bottom, fill='gray')
canvas.create_line(0, canvas_height/2, canvas_width, canvas_height/2, fill='white', dash=(20, 20))
# Create balls on the road
balls = [create_ball(canvas, ball_size, y) for y in range(int(road_top), int(road_bottom), ball_size*2)]
for ball in balls:
ball.update_lines()
ball.hide_text()
root.mainloop()