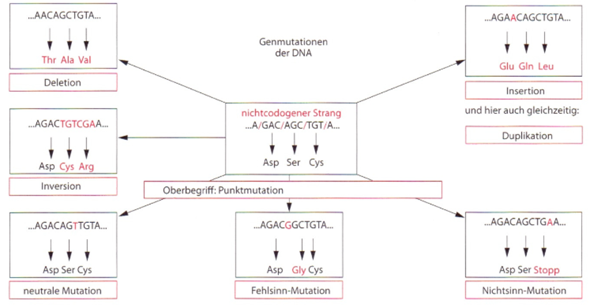
Warum handelt es sich hierbei um einen nicht codogener Strang?
LG
2 Antworten
Hi,
dazu muss man sich anschauen, wie die Übersetzung von DNA in Aminosäuren verläuft. Da steht, auf der DNA-Ebene sollen GAC Asparaginsäure, AGC Serin und TGT Cystein sein.
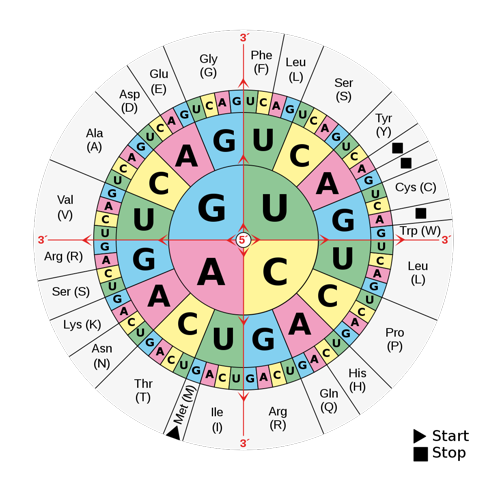
Wenn man nun in die Codesonne schaut, die die Basentripletts der mRNA für diese drei Aminosäuren angibt:
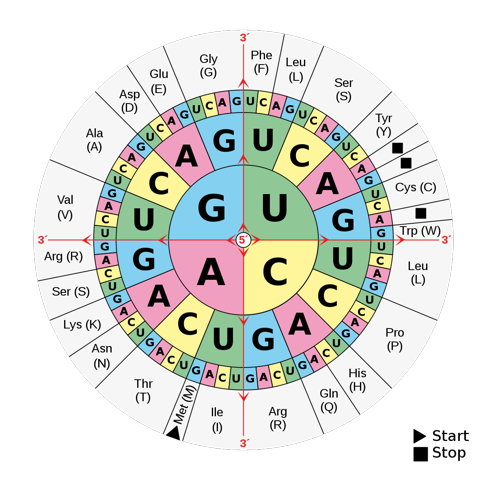
Bildquelle: wikipedia, gemeinfrei, link: https://commons.wikimedia.org/wiki/File:Aminoacids_table.svg
und mRNA-Tripletts für die drei Aminosäuren heraussucht:
Asparaginsäure = GAC (mRNA)
Serin = AGC (mRNA)
Cystein = UGU (mRNA)
dann sind das (bis auf Uracil) die gleichen Codes, wie es in der DNA sein sollen. Das bedeutet, dass es der codierende Strang oder der nicht-codogene Strang der DNA sein muss. Denn der nicht-codogene Strang und die mRNA haben, bis auf Uracil statt Thymin, die gleiche Basenfolge.
Man kann es auch herausfinden, indem man sich die Tripletts hintereinander schreibt, wie sie übersetzt werden:
mRNA: UGU und DNA: TGT können nur über einen komplementären DNA-Strang (den codogenen Strang) ACA in einen Informationsfluss gebracht werden:
DNA (nicht-codogen): TGT → DNA (codogen): ACA → mRNA: UGU → Aminosäure: Cys
Das gleiche gilt für die anderen beiden Übersetzungen:
DNA (nicht-codogen) GAC → DNA (codogen): CTG → mRNA: GAC → Aminosäure: Asp
DNA (nicht-codogen) AGC → DNA (codogen): TCG → mRNA: AGC → Aminosäure: Ser
Daraus geht hervor, dass die Basensequenz auf dem Arbeitsblatt, die des nicht-codogenen DNA-Stranges sein muss. LG
Weil es dort steht.
Das kann man nicht irgendwie sehen.
Vielen lieben Dank für die sehr hilfreiche Antwort 😊