Warum übertreibt GitHub so maßlos mit ihren Captchas?
Wollte heute einen neuen privaten Account erstellen und bekam 20(!) dieser Captchaaufgaben, bei denen eine nicht lösbar war.
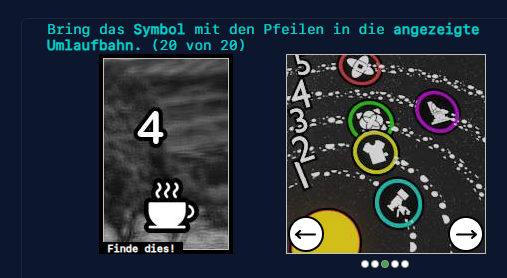
Zum Verständnis, die Linien haben Nummern. Man kann mit den Pfeilen die Symbole wechseln - es gibt keine Kaffeetasse und man kann deshalb dieses Captcha nicht bestehen. Nach 20 Aufgaben ist man dann doch etwas angefressen.
Stattdessen musste ich 20*3 Soundtracks anhören, um das 20-mal das plätschernde Wasser zu finden.
Warum ist GitHub bzw. Microsoft hier so extrem dahinter? Ein Bot sollte schon weniger Aufgaben nicht bestehen können, sonst wäre die Aufgabe doch unsinnig?
2 Antworten
Es geht nicht darum, dass die Maschine das nicht hin kriegt, es geht darum, dass die Captcha nicht auf "Schmuddelwebseiten" kopiert werden wo Menschen sitzen die dann den Captcha gezeigt bekommen mit dem Hinweis "Wenn Du das nächste Super-XXXXXX Bild sehen willst, dann löse den Captcha".
So kann man nämlich Menschen nutzen diese Captcha schnell und kostenlos zu lösen. Nur wenn da viele hintereinander kommen, dann wird das für Angreifer mit ihrer "Schmuddelseiten Schweinefarm" diese lösen viel schwieriger das erfolgreich hin zu kriegen.
Da gab es mal vor vielen Jahren einen sehr guten Vortrag darüber wie man Menschen kostenlos dazu bringen kann Arbeiten zu verrichten die ein Computer alleine nicht lösen kann. Menschen würden sogar Geld dafür bezahlen diese Arbeiten zu verrichten!
Danke! Das Video werde ich mir nachher auf jeden Fall anschauen!
Das ist bei OpenAi genauso schlimm wenn man sich neu registrieren will. Und dann schaffe ich zb alle 9/9 und trotzdem muss ich erneut anfangen aber immer 1 mehr. Ich glaube die haben große Probleme mit Bots und auch KI Bots die teilweise besser sind als Menschen darin sowas zu lösen.
Das fühlte sich an als würden die mich leiden sehen wollen.
Wenn sich jeder mit seinem Ausweis registrieren könnte wäre es gut aber dann ist die Privatsphäre dahin und sollte die Datenbank mal gehackt werden können die Hacker sich mit gestohlenen Identitäten anmelden.
Da ist viel mehr im Hintergrund, hier wird der ISP analysiert, die Anzahl der Verbindungen, Browser-Daten etc.
Wenn du beispielsweise mit einem VPN connected bist, wirst du trotz bestanden CAPTCHA manchmal nicht durchgelassen, passiert vor allem bei TOR.
Soweit ich weiß, ist das bei GitHub standard. Insbesondere weil ich den Edge Browser ohne VPN nutze und mein ISP O2 ist, wären die als Faktor eigentlich ausgeschlossen.
Das wird noch richtig interessant. Wie will man sich als Websitebetreiber in Zukunft wehren, wenn KI die Aufgaben besser lösen kann als wir selbst?