Approximativer Binomialtest, was wird hier gemacht?
Aufgabe:

Lösung:
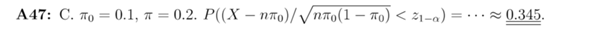
Der approximate Binomialtest seine Teststatistik ist so definiert:
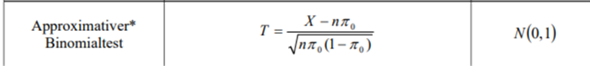
Was ich zunächst nicht kapiere, warum wurde das angewandt? Also was ist überhaupt X? Ich dachte vllt mache ich einen Test, dass die Wahrscheinlichkeit kleiner als 10% ist, also < 0.1 Tets, aber dann kam irgendwie die 20% dazu und ich verstehe garnichts mehr? Was sollen die 20%?
1 Antwort
Ohne auf die konkrete Berechnung einzugehen: n*Pi0 ist die Zahl, die das Auswahlkriterium für den Gemüsehändler bezeichnet, also hier 64*0,1 = 6,4. Er hofft also, dass er, wenn er eine Stichprobe von 64 Tomaten aus der großen Gesamtzahl von Tomaten nimmt, eine Aussage über die Gesamtzahl treffen kann.
Als Statistiker muss er von seiner Annahme ausgehen, eben maximal 10% unverkäufliche Tomaten in der Lieferung zu haben. Eine Stichprobe von 64 Tomaten kann dann natürlich auch weniger oder mehr als die angenommene Fehlerrate aufweisen, und hier geht es darum, die Ws zu ermitteln, dass bei angenommener Fehlerrate von 10% eine Stichprobe sogar Pi=20% oder mehr Fehler aufweisen kann. X ist damit n*Pi, als hier 64*0,2=12,8.
Die in Deinem Bild errechnete Ws liegt bei 0,345, so ein Quatsch, das hieße ja, bei mehr als 1/3 (0,333...) aller möglichen Stichproben von 64 aus der Gesamtmenge bekomme ich 20% oder mehr unverkäufliche Tomaten, wenn nur 10% in der Gesamtmenge sind. 0,345% = 0,00345 könnte eher richtig sein, ich errechne allerdings 0,00383 = 0,383%. (Z.B. http://www.arndt-bruenner.de/mathe/scripts/normalverteilung1.htm) (Auch bei den Intervallen A,B,C in der Aufgabenstellung fehlt das %-Zeichen.) Beide Ergebnisse liegen aber unter den geforderten 0,02 = 2%, sodass der Gemüsehandler in diesem Fall (20% oder mehr unverk. Tomaten in der Stichprobe) mit 98%-iger (100%-2%) Sicherheit nachgewiesen hat, dass mehr als 10% der Tomaten in der Gesamtmenge unverkäuflich sind.
P.S. Natürlich können nur 13 aber nicht 12,8 Tomaten unverkäuflich sein, und für X 13 statt 12,8 einzutragen, liefert natürlich eine geringfügig kleinere Ws, aber es handelt sich ja nur um einen approximativen Binomialtest, also einen angenäherten