Zählen von Wörtern in einer Zeichenkette?
Wieso kommt die Falschw Anzahl von dem gesuchtem Wort heraus, wenn ich das Programm ausführe und wie repariere ich das?
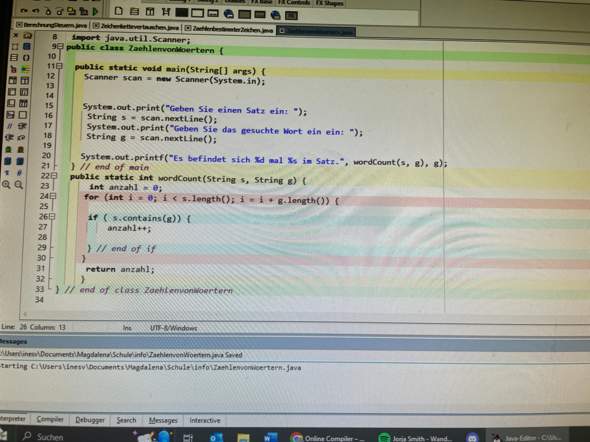
Als Beispiel kommt wenn ich als Satz eingebe: du und ich und die welt
Und nach dem Wort 'und' suche 8mal heraus.
6 Antworten
Naja, Du schaust ja immer wieder nur ob s g enthält. Du willst aber doch eigentlich schauen wie oft g in s enthalten ist.
Ich denke so müsste es gehen:
for (int i = 0; i <= s.length() - g.length(); i++) {
if (s.substring(i, i + g.length()).equals(g)) {
counter++;
}
}
Mal visualisiert:
s = Halloallo (Länge 9)
g = lo (Länge 2)
9 - 2 = 7, Schleife läuft also von 0 bis 7.
i=0: |Ha|lloallo
i=1: H|al|loallo
i=2: Ha|ll|oallo
i=3: Hal|lo|allo -> match, also counter++
i=4: Hall|oa|llo
i=5: Hallo|al|lo
i=6: Halloa|ll|o
i=7: Halloal|lo| -> match, also counter++
Falls überlappende Vorkommen nicht mitgezählt werden sollen (s="aaaa", g="aa" wäre dann 2 anstatt 3) ginge es auch einfacher, mit etwas Mathematik:
return (s.length() - s.replace(g, "").length()) / g.length();
oder noch kürzer:
return s.split(g, -1).length - 1;
Bitteschön :)
Aber ich denke ich habe die Aufgabe wohl falsch verstanden. Mein Code zählt, wie man an meinem Beispiel sieht, keine Wörter, sondern einfach generell wie oft eine Zeichenkette in einer anderen vorkommt. Wenn du wirklich Wörter in einem Satz zählen möchtest ist die Lösung von QLQuadratAchtel die einzig richtige.
ich erspare mir mal den einlesequatch
nur die ganzen uhu zählen:
String g = "uhufeder uhu esel uhu huhutle";
String s = "uhu";
Pattern pattern = Pattern.compile("\\b"+s+"\\b"); //suchwort innerhalb beliebiger wortbegrenzer (nur ganze Wörter finden)
Matcher matcher = pattern.matcher(g);
//java 9:
int count=matcher.results().count();
//bisJava 8:
int count = 0;
while (matcher.find()) {
count++;
}
System.out.println(count);
Ja, deine Schleife ist auch irgendwie seeehr merkwürdig. Du gehst in jedem Durchlauf so viele Buchstaben weiter, wie das gesuchte Wort lang ist und prüfst dann in jedem Durchlauf, ob das Wort irgendwo im String s vorkommt.
In deinem Beispiel ist der String 23 Zeichen lang und das gesuchte Wort ist 3 Zeichen lang. Es wird also insgesamt 8 Mal in dem Satz gesucht. Da das gesuchte Wort in dem Satz vorkommt, wird der Zähler jedes Mal um Eins erhöht und das Ergebnis ist 8.
Ich würde die Aufgabe am ehesten reguläre Ausdrücke benutzen:
ublic static int wordCount(String text, String search) {
return (int) Pattern
.compile(Pattern.quote(search))
.matcher(text)
.results()
.count();
}
Wieso machst du die Schleife so kompliziert? Lass den eingegeben Satz in einem Array oder Liste speichern, aufsplitten und anschließend durchloopen, ob g in s vorhanden ist, wenn ja, steigt der Zähler-Counter um 1 hoch.
String[] woerter = s.split(" ");
int zaehler = 0;
for (String w : woerter) {
if (w.equals(g)) {
zaehler++;
}
für einen einfachen Satz ohne kommas etc. ok. Bequemer/einfacher gehts mit regex, es gibt ja auch andere Zeichen, welche Wörter begrenzen können ein split an " " würde keien .;,?! .etc berücksichtigen. \bmeinwort\b findet nur ganze Worte, egal welche Zeichen drumrum sind
Ich hab es eben nochmal nachgeschlagen, da ich mich nur flüchtig mit Regex auseinandergesetzt habe. Ich wusste gar nicht, dass es mittels Metacharacters doch so einfach ist, danke! :D Wieder etwas gelernt.
Stimmt, wenns wirklich um Wörter in einem Satz geht sollte man das so machen. Ich glaube aufgrund seiner vorherigen Frage dachten wir alle, dass es darum geht, Substrings in einem String zu zählen.
Dankeschön das hilft mir sehr:)