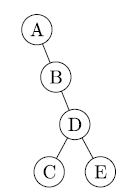
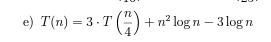In dieser Aufgabe betrachten wir gewurzelte ternäre Bäume. Jeder Knoten v kann also ein linkes Kind v.L, ein mittleres Kind v.M und/oder ein rechtes Kind v.R haben. Wir möchten nun herausfinden, wie viele Knoten im Baum sind.Gebe jeweils einen rekursiven Algorithmus in Pseudocode an, der durch den Aufruf count(v0) die Anzahl n der Knoten im Baum mit Wurzel v0 bestimmt. Begründe die Korrektheit der Algorithmen.
a) Gehe für den Entwurf deines Algorithmus zuerst davon aus, dass der Baum vollständig ist, also jeder Knoten entweder genau drei Kinder oder gar kein Kind besitzt und für jedes Blatt der Weg von der Wurzel die gleiche Länge hat. Stelle eine Rekursionsgleichung für die Laufzeit auf und löse diese mithilfe des Master-Theorems. Der Algorithmus soll eine Laufzeit von o(n)haben.
b) Wie verändern sich Algorithmus und Laufzeit, wenn Sie allgemeine ternäre Bäume betrachten?
________________________________________________________
Es geht um Pseudo-Code. In der Vorlesung benutzen wir C (obwohl wir C eigentlich erst nächstes Semester lernen), also wir lassen immer Klammern auf und schließen diese erst in der nächsten oder ubernächsten Zeile und erhöhen Variablen durch i++.
Ich habe mir überlegt, weil das ganze ein ternärer Baum sein soll und die Länge gezählt wird:
var counter = 0
for b = 0; b ≤ n; b++) {
for (l = 1, l++) {
l = l + 1
}
for (m = m, m++) {
m = m + 1
}
for (r = r, r++) {
r = r + 1
}
counter = counter + 1
}
wobei b die, ich nenn's jetzt einfach mal "Oberschleife" ,für den Baum an sich ist und l, m und r jeweils Unterschleifen, wobei l = links, m = mitte, r = rechts. Glaube aber, dass ich's mir hiermit zu einfach mache.
Zudem muss das Ganze ja noch als rekursive Funktion geschrieben werden, also der Form T (n) = a * T (n/b) + f(n), wobei b in diesem Fall = 3 ist, weil es ja ein ternärer Baum ist. Aber was ist a? Man könnte ja theoretisch unendlich viele Kinderknoten haben? Oder versteh ich da was falsch?